-- ����ʱ�䣺9/7/2004 10:09:00 PM
--
1.4 Denotations of Ground Graphs
The denotation of a ground RDF graph in I is given recursively by the following rules, which extend the interpretation mapping I from [URL=http://www.w3.org/TR/rdf-mt/#defname#defname]name[/URL]s to ground graphs. These rules (and extensions of them given later) work by defining the denotation of any piece of RDF syntax E in terms of the denotations of the immediate syntactic constituents of E, hence allowing the denotation of any piece of RDF to be determined by a kind of syntactic recursion.
ͼ��ָ�ɣ����涨����һ��ͼ�Ľ��ͣ���û�и���ͼ����ֵ�жϷ�����ָ�ɶ��巽���Ǵӻ������Ԫ�ؿ�ʼ��Ȼ�����õ���ĵݹ飬����һ��ͼ��ָ�ɡ�
In this table, and throughout this document, the equality sign = indicates identity and angle brackets <x,y> are used to indicate an ordered pair of x and y. RDF graph syntax is indicated using the notational conventions of the [URL=http://www.w3.org/TR/rdf-testcases/#ntriples]N-Triples[/URL] syntax described in the RDF test cases document [[URL=http://www.w3.org/TR/rdf-mt/#ref-rdf-tests#ref-rdf-tests]RDF-TESTS[/URL]]: literal strings are encloded within double quote marks, language tags indicated by the use of the @ sign, and triples terminate with a 'code dot' . .
Semantic conditions for ground graphs.
if E is a plain literal "aaa" in V then I(E) = aaa
if E is a plain literal "aaa"@ttt in V then I(E) = <aaa, ttt>
if E is a typed literal in V then I(E) = IL(E)
if E is a URI reference in V then I(E) = IS(E)
if E is a ground triple s p o. then I(E) = true if
s, p and o are in V, I(p) is in IP and <I(s),I(o)> is in IEXT(I(p))
otherwise I(E)= false.
if E is a ground RDF graph then I(E) = false if I(E') = false for some triple E' in E, otherwise I(E) =true.
If the vocabulary of an RDF graph contains names that are not in the vocabulary of an interpretation I - that is, if I simply does not give a semantic value to some [URL=http://www.w3.org/TR/rdf-mt/#defname#defname]name[/URL] that is used in the graph - then these truth-conditions will always yield the value false for some triple in the graph, and hence for the graph itself. Turned around, this means that any assertion of a graph implicitly asserts that all the [URL=http://www.w3.org/TR/rdf-mt/#defname#defname]name[/URL]s in the graph actually refer to something in the world. The final condition implies that an empty graph (an empty set of triples) is trivially true.
���˶Դʻ��е����ֽ��ͣ�����ݹ鶨��RDFͼ��ÿһ�䷨E��I�е�ֵ��
1. ���E ��һ��ƽ�����֣���ô I(E)=E��
2. ���E ��һ���������֣���ôI(E)= IL��E����
3. ���E ��URI,��ôI(E)=IS(E)��
4. ���E�Dz����սڵ����Ԫ��<s, p, o>���� I(E)=�� ���ҽ���s, p ��o ����V, I(p)����IP�� �� <I(s), I(o)>����IEXT(I(p))��
5. ���E��RDFͼ���� I(E)=�� ���ҽ��� ͼE�д���ij����Ԫ��E�� ʹ�� I(E��)=�٣����� I(E)=��
����Ҳ��Ϊ���͵���������������ʻ��д���ij�����֣�Iȴû�и�����ͣ����ͼ��ֵΪ�١����⣬��Ȼ��ͼ����ġ�
Note that the denotation of plain literals is always in LV; and that those of the subject and object of any true triple must be in IR; so any URI reference which occurs in a graph both as a predicate and as a subject or object must denote something in the intersection of IR and IP in any interpretation which satisfies the graph.
ƽ�����ֵ�ָ�ɶ�������LV�ģ���ֵΪ�����Ԫ�������Ϳ����ָ�ɶ�����IR�������һ����ֵΪ�ٵ���Ԫ�飬��û�����Լ���ˡ�
As an illustrative example, the following is a small interpretation for the artificial vocabulary {ex:a, ex:b, ex:c, "whatever", "whatever"^^ex:b}. Integers are used to indicate the non-literal 'things' in the universe. This is not meant to imply that interpretations should be interpreted as being about arithmetic, but more to emphasize that the exact nature of the things in the universe is irrelevant. LV can be any set satisfying the semantic conditions. (In this and subsequent examples the greater-than and less-than symbols are used in several ways: following mathematical usage to indicate abstract pairs and n-tuples; following N-Triples syntax to enclose URI references, and also as arrowheads when indicating mappings.)
IR = LV union{1, 2}
IP={1}
IEXT: 1=>{<1,2>,<2,1>}
IS: ex:a=>1, ex:b=>1, ex:c=>2
IL: "whatever"^^ex:b =>2
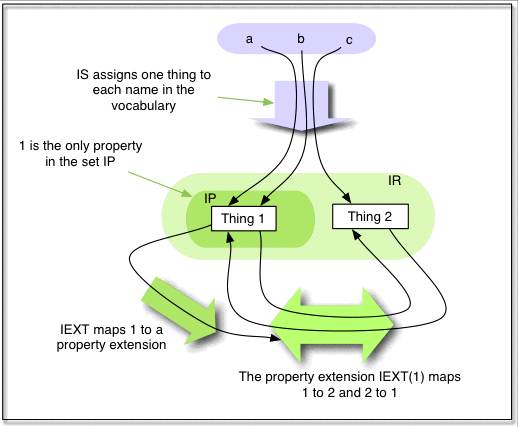
Figure 1: An example of an interpretation. Note, this is not a picture of an RDF graph.
The figure does not show the infinite number of members of LV.
This interpretation makes these triples true:
<ex:a> <ex:b> <ex:c> .
<ex:c> <ex:a> <ex:a> .
<ex:c> <ex:b> <ex:a> .
<ex:a> <ex:b> "whatever"^^<ex:b> .
For example, I(<ex:a> <ex:b> <ex:c> .) = true if <I(ex:a),I(ex:c)> is in IEXT(I(<ex:b>)), i.e. if <1,2> is in IEXT(1), which is {<1,2>,<2,1>} and so does contain <1,2> and so I(<ex:a <ex:b> ex:c>) is true.
The truth of the fourth triple is a consequence of the rather idiosyncratic interpretation chosen here for typed literals.
��Щ��Ԫ����������������¶�����ģ����ڱ�ģ��������£��Ϳ���Ϊ���ˡ��������������¶�Ϊ�棬��������ȫ��ʽ�������RDF���ͣ�RDFS���ͻ��ᵽ��
In this interpretation IP is a subset of IR; this will be typical of RDF semantic interpretations, but is not required.
һ����˵IP��IR���Ӽ�����Ϊ����Ҳ���Ե�����Դ����Ϊ��Ԫ����������壬���Ⲣ���DZ���ġ���Ϊ�������ҵ�ͼ�У����������е����Զ���Ϊ���������塣
It makes these triples false:
<ex:a> <ex:c> <ex:b> .
<ex:a> <ex:b> <ex:b> .
<ex:c> <ex:a> <ex:c> .
<ex:a> <ex:b> "whatever" .
For example, I(<ex:a> <ex:c> <ex:b> .) = true if <I(ex:a), I(<ex:b>)>, i.e.<1,1>, is in IEXT(I(ex:c)); but I(ex:c)=2 which is not in IP, so IEXT is not defined on 2, so the condition fails and I(<ex:a> <ex:c> <ex:b> .) = false.
It also makes all triples containing a plain literal false, since the property extension does not have any pairs containing a plain literal.
����������£������Ԫ�����м����֣���Ϊ�٣���Ϊ���ԵĽ��ͺ�����IEXT����û�а�������ļ����֡�
To emphasize; this is only one possible interpretation of this vocabulary; there are (infinitely) many others. For example, if this interpretation were modified by attaching the property extension to 2 instead of 1, none of the above triples would be true.
һ��ͼ�Ľ�������������
This example illustrates that any interpretation which maps any URI reference which occurs in the predicate position of a triple in a graph to something not in IP will make the graph false.
�������û�а�ν��URIӳ��Ϊ��IP���������ν�ʵ���Ԫ��϶�Ϊ�١�