-- 发布时间:9/26/2005 9:40:00 AM
--
这几个问题提得很好。虽然问题simple,但回答起来not easy
这几个问题确实应该给大家一个明确的答案。我提议大家尽量回答,当作一种讨论,之后我会把我们的讨论结果反馈给W3C,看看它们的看法。声明一点,就是,这类问题的回答,没有绝对的对与错,希望大家踊跃的参与进来。
1.语义Web到底有什么优越性?(很少看到非常能说服人得)
看了一段时间,给我印象最深得应用就是,同义搜索,还有就是比如搜索联系方式,由于事先编写得OWL定义了联系方式得一些子方式,所以搜索时把这些子方式都列出来。其他得感觉跟现有得应用在很多方面没体现出什么优越性,而且还有很多限制,如数据存储方面,共享,搜索速度。
2.语义web扩展性表现在哪里,哪些方面?
3.语义Web的开发过程和传统的开发过程有什么区别和联系?有什么优越性?
5.语义web可以用于解决哪些问题?能解决哪些问题?
6.语义web面临的问题、难题?
7.Web Service的组装与数据集成,用语义Web技术解决与用传统方法解决有什么优越性?
利用SW技术,可以进行更加准确的服务匹配
8.语义web在数据挖掘上优势在哪里?
http://bbs.w3china.org/dispbbs.asp?BoardID=2&replyID=17073&id=8403&star=1&skin=0
http://bbs.w3china.org/dispbbs.asp?BoardID=2&replyID=18743&id=8810&star=1&skin=0
9.有一个研究语义Web很长时间的学者黄智生说,语义是什么?语义就是共享信息,现阶段从软件的发展过程中从组件到Web Service 到SOA,都在强调一种共享、重用, 语义Web的共享和重用与SOA、Webservice的共享和重用之间有什么区别和联系? ?
SW是要令Web上的信息成为机器可理解的,因此机器可以根据这些信息为人类作一些推理,挖掘出一些潜在的知识。这里的共享是知识层面的共享,参与共享的是:人-机器-机器-人
WS的共享指的是实现可重用的服务。共享的是服务
10.当前版本OWL有哪些推理还不能做?支持到哪个程度?
*各个版本的OWL不同,OWL LITE, OWL DL, OWL FULL在推理上的困难依次增加
*TBox的推理要远远快于ABox(即涉及individual的)的推理
11.本体库,知识库,语义网”之间的联系是什么??
12.RDF和OWL是什么关系?
![]()
RDF和OWL不是一个层次的东西。
除去那些复杂的特性,最简单地来看,
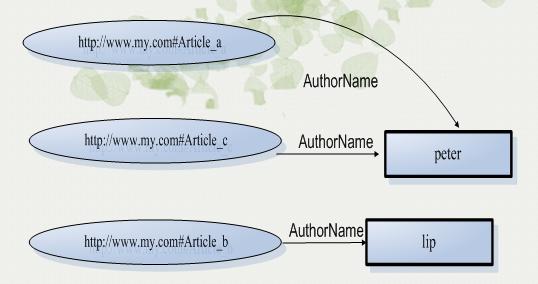
RDF提供的是一组 (主,谓,宾)这样的断言
而OWL提供的是一个分类层次(比如 苹果 subClassOf 水果, 水果 subClassOf 食物 等等 )
当然这些并不是RDF和OWL的全部,而只是简化地来看。
 此主题相关图片如下:
此主题相关图片如下: