ԭ�ģ�
http://www.w3.org/People/Berners-Lee/1996/ppf.html ��ά������ȥ�����ں�δ��
Tim Berners-Lee 1996��8��
���Ϊ����ӦIEEE�����1996��ʮ���ؿ������������д�ģ�����������һ���ؿ�������ˡ�
ժҪ��
��ά������Ƴ���������Ϊ������Ϣ�Ľ��������磬����������������ܹ��������ͬʱ���ܹ��������������1989����������������������Ϊһ��ý�����������ڸ߸��ص���ҵ�������ϵ�ֻ�����ϵĹ㲥��չ����ʹ��Internet���ӵ������ߵĴ���ý�塣�������ҵ�϶���������֯�е�Ӧ�èD�D������ν�ġ�Intranet������Ȥ���������˸�С�ģ���յģ�����ض���֯����������������и����������������Ľ�����������������������ά����Ϊ��С����֯����ͥ������Ϣϵͳ�Ĺ��ߡ���������Ȥ�ķ�չ�������û��ӿڵ����������Ŀɽ����ԺͰ����Ѷ������ԵĻ����ɶ�����Ϣ�����ã�������Ϣ�û����ܹ����õĴ���ȫ�����Ϣ��������Ϣ�л������Ի����ɶ��ķ��ű���Ķ��ԡ�
����
��ƪ���´��������ߵĸ��˹۵㣬������W3C��֯��Ա���߷��������µĻ����Ĺ۵㡣
��ƪ�����������ά������ʷ����״�Ϳ��ܵķ�չ������ά���Ķ���Ϊȫ���Ե�ͨ��������Ի�ȡ����Ϣ���ܺ͡�����һ��ͨ���������ܹ������ij���Ŀռ䣬Ŀǰ������Ҫ����ʽ���ڲ���������ı���ͼ��Ͷ�����ż��������������ά�������Ƶ�����Ĵ��ڱ�־�����˾�ɥ�����˸е������ļ����ϵͳ֮������Ӵ���ʱ���Ľ������������ǵı�����DZ�ڵĶ����Ծ��õ�Ӱ�첢û����Ȼ��ȥ��˿������ע�⣬�෴����������ǰ�Ѿ�ʹ�õ��Եĸ����Ⱥ������ע�����ϵͳ��DZ�ڵ��̻��Ѿ��շ��������ԵĿ����ķ�չ��ʹ��ά����ά����������ȫ���ԵĽ���������Ϊ���й�ע�߳��ڵ�����ͬʱ����������һЩ��Խ��Խ������Ҫ����������о�������Щ���ǽ�ֻ����������˳���ἰ��������ŵ��һ����������������ƻ������Ŀ�꿪ʼ�����Ŀ��Ĺ�˼����Ϊ�������߸�����Ҫ����֯���ɿ�ѧ���빤��ʦ��ɵĸ�������������ʶ������Ҫ��������˵ȫ�������Ҫ��
��ʷ
����ά��֮ǰ
���ı���˼����Դ�ܹ��ݵ���ʷ�ԵĹ���������˵Vanevar Bush ��1945�귢���ڡ��������¿��ϵ����������¡�As We May Think��������ƪ�����У��������ͨ���Զ����Ʊ��롢���ܺͼ�ʹ��Ӱ���Ĵ������ܹ�ʵ������Ƭ������ú��Զ���������Ӧ�õ�Memex����������������Doug Englebart��ʹ�����ּ�����ṩ���ı��ʼ����ļ������ġ�NLS��ϵͳ������ġ����ı����ĸ���õ���Ted Nelson ����������������Щ˼�룬���ǹ�����ʵ���籾���ĸ�����������ȴ�������籾������һ����һ�µ����磬���̸�ʽ�����ݸ�ʽ���ַ����뷽ʽ�����еij����ڲ�ͬϵͳ֮�䴫����Ϣ��������η����һ�㿴���Dz�ʵ�ʵĹ�������������Խ��Խ�㷺�����ڴֵ���Ϣ���������������ڼ���������֪�����κ����鶼���һ����¼��ij���ط����⽫���ر����˾�ɥ�ġ�
��Ʊ�
��ά����Ŀ���dz�Ϊ���ǣ��ͻ������ܹ�������Ĺ�������Ϣ�ռ䡣
Ŀ��������ռ�Ӧ�ú��˽�е���Ϣϵͳ������Ϣ������ֵ�ߵ���ϸ������ƵIJ��Ϻ�ֻ�Ƕ���һЩ��������Ҳ���Ժ�û�˻��ٿ��ļ�ϯ��˼�롣
��ά������ƻ���һЩ����
• �����Ϣϵͳһ���ܹ���¼���κζ���֮����������ϵ�����������������ݿ�ϵͳ��
• ��������û���ʼ������ʹ��ϵͳ����һ��ϵͳ����һ��ϵͳ��������Ӧ����һ�������ԵĹ�����������Ҫһ�����������IJ���������˵�ϲ�����ӵ����ݿ⡣
• �κ�Լ���û�ʹ���ض����Ի����ض�����ϵͳ�ij��Զ�ע��Ҫʧ�ܣ�
• ���е�ƽ̨���ܹ���ȡ��Ϣ������δ���ģ�
• �κγ���Լ���û��������ݵ�˼άģ��Ϊijһ�ض�ģʽ�ij���ע��Ҫʧ�ܣ�
• �����֯����ϢҪ��ϵͳ�еõ���ȷ�ı��������߾�����������ȷ��֪����������˵����������¡�
���ߵľ������ʹ�úܶ�������ѧ�����˽�е�ϵͳ��ͬʱ�������Լ�������������ӡ����ڸ��˷dz����õ���δ���㷺��ʹ�õ���ѯ����1980����
�����ά����һ��Ŀ���ǣ�����˺ͳ��ı�֮��Ľ����Ƿdz�����ֱ���������ڻ����ɶ�����Ϣ�ռ侫ȷ�ı��������ǵ�˼ά����������ģʽ��״̬��Ȼ�����ķ����ܹ���Ϊ����ǿ��Ĺ��ߣ����������ڹ����е��ੲ��ݵ�ͬʱ�ٽ�����һ������ͳ�������Ŵ�����֯�����⡣
�����ܹ�ԭ��
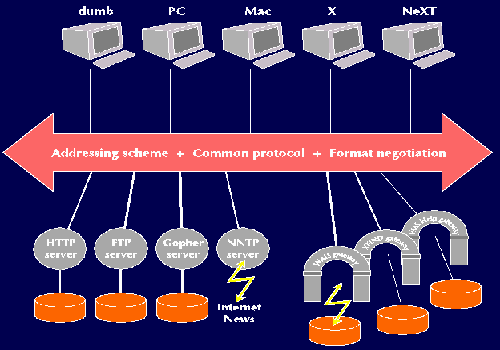
������1989���������ά���ļܹ���ͼʾ���¡���һ�ܹ�����ƾ���Ϊ����������ı���������һЩ�ܹ������������������֪���������ԭ����
ͼƬ��1990����������ά���ܹ�ͼ����ɫ�ļ�ͷ����ͨ�õı���URL��HTTP�����ݸ�ʽԼ��
�淶�Ķ�����
������Ȼ���ص㡣ÿ���淶��Ҫ��֤Լ����ά����ʵʩ��ʹ�õĻ������ԡ���ˣ��������ٵĶ�����Ҫ�ر�Ĺ涨����СԼ������������Щ�淶Ӧ�ö������ƶ���ģ�黯����Ϣ���أ����淶�Ķ�����Ӧ��������Ƶ�һ�����ڱ�������ܹ���ͬʱȡ����Ƶ��κβ��֡�������������һ�ֲ��Է������ԾɵĹ淶������еģ�����ʾ���Ǻ��¹淶���ʹ�õ��������������ڵ�ַ�ռ��ϣ��ɵ�FTPЭ���ܹ����µ�HTTPЭ����ʹ�ã���ͳ���ı��ļ��ܹ����µij��ı����ʹ�á�
ֵ��һ�������СԼ��ԭ���DZ�֤��ά���Ŀ���Ӧ�Ե���Ҫ���ء��������ֹ۵㣬������Ҫ��һЩС�������ĸı���ʹ����ά������ʼ��Ϊ������ϵͳƽ�еļ�����Ȼ�������Ϊ������ϵͳ�����ִ��ڻ���ԭ���Ŀ���´ӹ�ȥ�����ڵĽ�������ʹ���������������Ŵ�������δ��������һ����˳����һ���Ļ�����ߡ�
ͳһ��Դ��ʶ����URI��
���ı��ĸ��������Ѿá���ͳ�ģ����ܳ��ı���ϵͳΧ���Ű������ӵ����ݿ�������ģ����Ǵ���������ĽǶ���˵���Ⲣû����ϸ�������к�����Ȼ����ȷʵ��֤������Ӧ����һ�µģ����ҵ��ĵ���ɾ����ʱ������ҲӦ�ñ�ɾ�������ֿ��Ƴ�����������ά���ܹ���ԭ���Ե���Э����������ͨ�������������ö�������������Դ��ͬ�⣬��֤�˺�����ά��Ѹ�����ź�Ŀɶ����ԡ�
��ά�������ӵ����������ܹ�ָ����Ϣ������κθ�ʽ���κ��ĵ� �����Ҫһ��ȫ�ı�ʶ���ռ䡣��ЩURI����ά���ܹ��е���ҪԪ�ء�����������֪�Ľṹ��һ��ǰ����˵��http:����Ϊ��ͷ�Ա����ַ�����ʣ�ಿ����ָ��Ŀռ䡣URI�ռ���һ��ͨ�õĿռ䣬������ռ����κ�һ�־��б�ʶ��������Ѱַ������µĿռ䶼�ܹ���ӳ�䵽һ���ܹ�����������������һ��ǰ��Ȼ�����ܹ���ΪURI�ռ��һ���֡��κθ�����URI������ȡ��������ָ��Ŀռ�����ԡ�����Щ���Ծ�����һЩ�ռ�����ǡ����ơ��ռ䣬��һЩ�����ǡ���ַ���ռ䣬���ǿռ����ǵ����Բ�����ȡ�������Ķ��塢���֧��Э�飬��ȡ����֧���������ṹ�Լ���ʶ���ķ�����ٷ������Ϊ�Ķ��塣���˵��ǣ���ά���ܹ�����ȡ����URI���������ǻ����ǵ�ַ������������IETF ��Internet���������飩�ƶ��ġ�URL�� ����Ŀǰʹ�õĴ������URIs�������ָ���ַ���������֡������ڴ���һ�ֹ��ܸ���ǿ��������ռ�ij��֣�����ֵ��ע������Ⲣ������������¡�
��ʶ���IJ�����
һ����Ҫ��ԭ��URIͨ���������Dz������ַ������ͻ������������������ı��ʣ�Ҳ���ܸ�������ù���Ӧ�õĶ���Ľ��ۡ�
һ���URIs
URIs����һ����Ȥ�����������ܹ�һ���Եı�ʶ�������ĵ��������磬�����ܹ�Ϊһ����ָ��һ��URI�������URI�������ö�������д�ɵģ��������������ݸ�ʽ������Ҳ��Ϊͬһ����ָ��һ��ʹ���ض����Ե�URI������Ϊ�Ȿ���ij���ض��汾�ı������ı�����ʽָ��ʹ��ij�����Ժ����ݸ�ʽ��URI��������һ����ά������ġ���ʶ���������ǵ���һ���ԣ������������ϵͳ����һ����
HTTP
���ڻ�ȡԶ�����ݵ�Э�飬��ȥ��������һ���������ļ�����Э�飨FTP���� Ȼ����������ά����˵�ⲻ�����ŵģ�����ά������̫���ˣ����������ʹ��ڲ��㣬�������Ҫ�����һ���µ�Э��������Դ��䳬�ı����Ŀ��ٳ�������Ҫ�����ı�����Э�鱻��Ƴ��������ǰ�HTTP URIs�ֳ��������֣�����ָ��Ѱַ���ĵ�����һ����������������������ʺϵķ��������ڶ�������һ���ɷ����������IJ������ַ�����
HTTP��һ���������������ͻ��˴����Ժ����ݸ�ʽ�Ƕ���ϸָ�������������������ܹ��ڱ������URI����һ���Ե�ʱ��ѡ����ʵ��ض��������������ںܶ��HTTP��������ʵ���ˣ������ڿͻ���δ��������ã�����ԭ���Ǵ�����Щ������Ҫ��ʱ��̫�࣬����ԭ���������ȵ�һ���URIsû��������Щ��������һ���ԣ�������ν�ĸ�ʽԼ������HTTP�淶��HTML�淶֮���������һ����ҪԪ�ء�
HTML
Ϊ�˽��г��ı������ݽ�������������˳��ı����������Ϊ��������ݸ�ʽ������������Ϊ����д�� ���ǵ��ᳫȫ����ʹ��һ��ȫ�µ�ȫ����Ϣϵͳ�Ŀ��ܵ����ѣ�HTML�����ڻ���SGML��ϵͳ�Թ����ļ�����ʹ��������������������ʹ��SGML��Ϊ����ͬʱ��ҲΪ���ó��ı�����ʹ�����������������ΪSGML��Ψһ���ܵĸ�ʽ�������ܲ���SGMLȷʵ��ʹ����Щ��֯�����Ľ�����ά��������SGML����̫�����ˣ�����ȱ��һ�ֶ���õ������SGML����ȫ�ı���������HTML��������֮��Ѱ����������������ר���Ǻܳ�ʱ�䡣
������ʷ
�Ӹ���������������һ˼��Ĺ��������۵ģ�������ά����˵�����ķ�չҲ����������˵��ÿ��������ǰ����ʹ��ϵͳ��Ҳ���ǽ���ӵ�����������ڲ���ֻ�ܱ�������������������������Բ����ܵġ��䷢չ��һЩ�����¡�
• �����ԭ�ͳ�����NeXTStepϵͳ�У�1990��10�£�12�£�����Ϊһ���ܹ�ͬʱ��������������ã�wysiwyg���༭���ߣ����������Ӽ����Ӻ��ĵ���Ȼ����NeXTStep�Ŀɲ����������������Ŀɼ��ԡ������������������ά��ʹ��������߱�д���ܹ����ӵ�������ͼ���ļ������ҷ�����һ����HTTP�������ϡ�
• Ϊ��ȷ���ܹ��ڵõ�ȫ��Χ�Ľ��ܣ�Nicola Pellow������һ����ν�ġ�����ģʽ���������������������������ά����Ϣ�����κ�ƽ̨�����������ij��ı��������������Ǹ�ʱ���ܶ�������������ά������1991�꣩
• Ϊ�˸���ά�������֡����ݣ����ǿ����˵ڶ�����������CERN��������¸��̳��Եĵ�ַ�����ݿ��ṩ���ء����ǵ�һ�������á�����ά��Ӧ�ã���ʱ��ܶ��˰���ά��������һ����������û�����ĵ绰������Ȼ����ʹ��һЩ����ģʽ����������������档�������ط������Ժ��ֳ��������ļ��֣���Щʹ����ά���ͻ���������������֯�ڲ���Ϊ���õĹ��ߡ�
• ����CERNû�и���Ŀɻ�ȡ����Դ����֯��ʱ��Internet�����ձ���յ���������ά��������ֲ������ƽ̨��X windowsƽ̨��"Erwise", "Midas"��"Viola-WWW"��Windows(TM)ƽ̨��"Cello"���Ǹ����о�����Ŀͻ��ˣ����Dz��ҵ������ǽ����������������PeiWei�������Viola-WWW����Ȥ���ǻ���һ�ֽ����Ե��ƶ��������ԣ�Viola��������ij�̶ֳ����ܹ��ͺ����ĺ����ŵ�Java��TM����ȡ�
• �ܳ�һ��ʱ�䣬Internet Gopher ����Ϊ�ǿ�ѡ����Ϣϵͳ����������HTML�ĸ����ԣ����ǹ��ڼ�����ҥ�����������Ƕ�����ȫ�������������
• 1993������ȫ�����������Ӧ�����ĵ�Marc Andreessen�ڿ���ViolaWWW�Ժ�����"Mosaic"������һ������X����ά���ͻ��ˡ�Mosaic�dz����װ�װ������֧����ǶͼƬ����÷dz����С�
• 1994�꣬Navisoft����˾������һ�������м��������������ͱ༭�������ܹ���ͬһ��ģʽ����ʾ�ͱ༭�������Ŀǰ������֪�ġ�AOLPress������
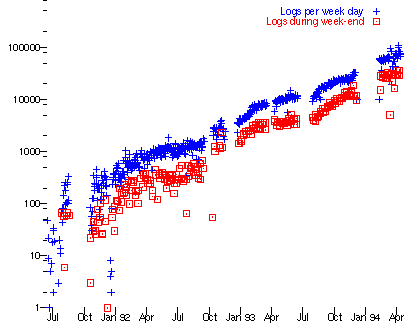
һ�����ڵ���ά�����������ͳ������info.cern.ch�ϵĵ�һ����ά���������ĸ������ͳ�� �������������Ŀͻ���������ͬһ̨����������������ַ��www.w3.org������ֵ��ǣ���ͼ�ɼ������ԵIJⶨ�������ȶ���ָ��������ʽ������������ÿ������ʮ�������������DZ�ը�Եģ��������Ǻ���˵�������һ������������ڸ������塣
ͼƬ����1991��7�µ�1994��7�£���ά���ͻ��˵�����������հĵ��Ӧ�����ݶ�ʧ��������ĩ�����յ���������Ҳ�Ƿdz��ȶ���
�Ǹ�����������һЩѰ�Һ����пͻ��˺ͷ������Ľ��顣�����������ܹ�����һ��ҳ�棬���ҳ���а���һЩԼ��������˵�����ṩ���ڷ���������ѯ�ġ��������Ա�����ʼ���ַ������˵�����Ƿ��������Ƶ��Ǹ�URLĬ�Ͼ���ϵͳ����ڣ������ܷ������ڲ����ӵ����˽ṹ��Ρ�
�ⷢչ����һ����ڶ�֪������ʣ�µĸ����ĵ��о��кܺõļ�¼�ˡ�HTML���ֻ������Ϊ�����ḻ�������������͵ij��ı���Ƭ֯��ǰһƬγɴ�Ķ��������˾��ȵĵ������ڡ���ά����ʼ��Ԧ����������Ժ�internet�������Զ��������������ǡ���http:���������͵�URL�����800����һ���������������Լ���
��״
���������ܽ�һ����ά��Ŀǰ���о������һЩ����ķ�չ��
�����ݺͽ���
URIs��HTTP��HTML��Щͨ�õı�ʹ����ά��Ѹ�ٵ����ţ�Ҳʹ��ȫ������ҵ�ʹ�ѧ����Դ�ܱ�������ά���Ŀ�������չ������˴����µ��������ͺ�Э��ij��֡�
�����ݸ�ʽ��������˵HTTP�Ĵ��������������͵�����ʹ�����ܹ�������չ�����Ա���˵��λ������������VRML�������ڴ����ƶ������Java(TM)�����������Ҳʮ�����ס��������Ƿ�����֪��Ҫ֧��ʲô���Ŀͻ��ˣ���Ϊ��ʽЭ��ϵͳ��û�й㷺�IJ����ڸ����ͻ��ˡ���͵����˱���˵һЩ���Ĺ���ʵ���������ڷ���������Ҫά��һ�������������������ܺͰ汾������ʹ�������µ��������ú����ѣ�ͬʱ��Ȼ��Ҳ���Թ�����������µ�δ���ܶ����˽�Ŀͻ���Ϊ�˻�ȡ�������ε��㹻�ḻ�����ݲ��ò��ڷ�������ǰ��αװ����һ��������֪���������ͬʱ��������MIME�����������Ͳ���ֵ����⣺text/html���������ܶ��ε�HTML����һ��ͼƬʹ�ö�����ɫ���������ǵļ�����Ȥ��ʱ��image/pngȴ���ڱ�ʾ�κε�PNG��ʽ��ͼ��Java��TM���ļ���������ȴû���κοɼ��Ĺ�������ʱ����Ҫ֧�ֵ�˵����
�ƶ������Ժͽ���������
��1992�꿪ʼ������ҵ�綼ǿ�ҵĵ�����ά�����ķ����Խ��ƻ�����ô�������������ҵӦ�õĻ�������Ϣ����������д��֮ʱ�������֯�а���������ά����������Ҫ�����ߺ�������һЩ����ҵԽ��Խ������ά�����ձ��Ժ��ܵ�150�����ҵij�Ա����������MIT��ŷ��Institute Nationale pour la R��cherche en Informatique et AutomatiqueΪ���� �������֯Ϊ���������ҵ�ṩһ��������������Ϊ�˹����������ֹ����淶����̳�������֯��������ʵ����ά����ȫ��DZ���������Ǻ����н��ܵķ�չ����
�ӱ�����С����֤������PICS
��ʹ����Э�鷢չ����ʱʱ�����ܹ��ļ�����Ҫ������˵��Ч�Ļ��棬������һЩ�����Ӧ�ã�����ʱ����ά�������Ľ������������֮�����ϵ�� Sometimes these become interleaved.��ʱ����Щ�ǽ�����ڵġ����ߵ�һ�������Ƿ�ӳ�ҳ���ѧУ�������������ͯ�ܹ���ȡ���ϵ��������������������ı���Ϊ�Ƕ������к��Ķ����ĵ��ǡ�����������InternetӦ�õ���в���߸������ߣ���������£���֯Ѹ�ٵ�������Ӧ��ָ����W3C��Internet����ѡ��ƽ̨��Platform for Internet Content Selection ��PICS����PICSΪ��ά���ܹ��������µ�Э��Ԫ�غ����ݸ�ʽ��������صĿ�������δ����չ��ԭ���ṩ֧�֡�
�����ϣ�PICS�����ҳ�Ϊ���ǵĺ��ӵ���Ϣ������ù��ˣ���Щ�����ܹ��������ĵȼ�����ӳ���ҳ���ѡ���ϡ����ַ��������ǵ������ҳ�������������������Ϊ���Ӷ���ʲô��̫����������������Internet����ά��һ������һ�ֲַ�ʽ�Ľ���취��
�����Ͻ���PICS����һ�������ɶ����ı����Ĺ淶������HTML��PICS�ı���Ƶ�Ŀ���Ǹ������Ķ��������������Ķ������������ԡ�ֵ�Եļ��ϣ��������������ģ������κΰ���URL���ı��ڼ��ʱ��ͬʱ�ṩ�������˿ɶ��Ķ������ԺͿ��ܵ�ֵ�������˵����
ͼƬ��RSAC-i�ĵȼ����š�һ��PICS��ʽ�����ӣ���ע��ԭ��ͼƬȱʧ��
PICS��ǩ����ʹ�úܶ����ȡ�����ǿ��ܱ���CD��ROM�ı��棬���������ܹ������ע��������ϵķ��������ͣ�PICS ��ǩ���������ֻ��ķ��ţ��������ǵ�Ȩ�����ܹ������ǵķ��з�ʽ�Ķ���������֤��������Ҳ�ܴӵ�����ʵʱ�Ļ�á������Ҫһ��Э���˵����������֯��
�ܹ�����֯B��ȡ�κ�����֯C��������Ϣ�ı�ǩ��
�����ԣ���������ڹ���ͨ�ŵ������Ե�ѹ��֮�ºܿ�صõ�Ӧ�á����ܹ��ںܶ���������õ�Ӧ�á���ǩ��ѯЭ��ͱ�ע����Э����һ���ġ�һ�����𣬱�ǩ�������ܹ��ڱ����ǩ��ͬʱ�ṩ��ע���������ܹ�Ϊ���Ϻ�ѧ��ʹ�öԲ��Ͻ����������γɡ����ϱ�ǩ�����ø��˸����ǵ�ѡ�����ǵĶ��
��ȫ�͵�������
�������ͨ��������Ϣ��Ǯ����������ά���������ǽ�����Ϣ����ˣ���һ���Ǻ���Ȼ���ǽ���Ǯ����ʵ�ϣ�������ֽ����Dz��ɶ���Ļ��ң����ֻ��Ľ����Dz����ܵġ����Ǻܶ���ܻ����ṩ�Գ�ŵ�ĵ����ķ���ʹ�������ܹ�����֧Ʊ�������ÿ���һЩ�µ���ʽ��֧���ֶΡ���ƪ���������Dz�������ϸ��������Щ������Ҳ�������������ڱ�֤���簲ȫ�ĸ��ַ����� �����Ա�֤�����ԡ���Ȩ�����ɵ�������Ϣ��������������������еġ���״��Ŀǰ�кܶ���������ر��Э���Ա��ϰ�ȫ������֧����˵��Ҳ��Խ��Խ���Э��ɿɹ�ʹ�á�һ��Э��Netscape�ġ���ȫ���֡���Secure Socket Layer ��SSL����֤�˻Ự�Ļ����ԣ��Ѿ��õ��ܺõ�Ӧ�á�Ϊ�˱�֤����չ�ԣ�W3C�����о�һ���ݰ�������ʹ���Ǹ���ȫ֧��Э�顣
��������ά���Ľ���
����Ϊֹ����������ά������Ϣ�ķ�������Ҫ��������ʹ������������л����ı��ı�������֤�ݱ��������������Ƿdz����õģ������������У������ܹ��Ծ����������м����Է��ֲ����ĵ���Ҳ��֤��˵�����������õģ���ʹ�����ǽ�������ʱ�������������ļ��еĴʻ㣬���������������ĵ�����������˲����˺ܶ�Ц��������������������ά�����Ӱ������ʶ����������ĵ�������֧�ָ�ǿ��Ĺ��ߡ�
һЩ��ص���ǰ;��˼·ʱ�Ȱ�������ά���ķ�����������������������ά�����н��������Զ���ȡ��صĸ���������Ϣ��һЩ�������͵Ĺ��ߣ������������߱�����Ϊ�������塱����Ϊ���ǰ����û�����Ϊ�����������ܡ������塱�������һ�����ڿ��ƶ��ij������ڼ���û��ͨ�õĿ��ƶ��������塱���ƶ��������ڽ�����Ȥ�������˻��ӿڣ�����Java��Applets����ʹ���û��ܹ������µķֲ�ʽ��Ӧ�á��ƶ�������ڹ��ڿͻ��˺ͷ����������������ܹ��и����DZ�ڵ�Ӱ�졣Ȼ����û��һ��ִ�а����û���Ϊ���е��ƶ������߾��ǹ̶�����ά���������Ŀ������磬������dz����ޡ�
�����
���ܽ�����ά������Դ��Ŀǰ״̬֮����������������һЩ���ܵĽ����������ķ�չ���������ܰ���Щ����ֳ��������ڵ�Ŀ�ꡣ��һ������������ʩ�Ľ������ṩһ�����ܸ�ǿ����������Ч�Ŀɻ�õķ��ڶ���ǿ����ά����Ϊ���ǽ����ͽ������ֶΡ���������ʹ��ά�����˳�Ϊ���ǿ�����Ŀռ��⣬�����ḻ�Ļ�����������ʽ����Ϣ���������������ܹ��ڷ�����ά���������������ã��������ǽ�����⡣
������ʩ
��ά�����֮������Щ��ʵ����Ҫ���ԣ�ʹ����ά���Ŀɶ����ģ��κ����ܹ�����һ��������������Ҫ���κ�������Ȩ����ע����ܹ����ֵ����У�Ҳ����Ҫע�������˵�HTTP��������������������ֿ��������Dz����ģ��ͻ��˵���������˾������ڶ��ڷ��������ܲ����Ĵ������ڿͻ��˵������ء�������������ĵ��Ķ��������dz��������ڷ������ĸ��ر�������ܡ�
���⣬Ϊ��ʹ��ά����Ϊ��ʵ��������õķ�ӳ��һ��Ҫ�ܹ������Բ�ͬ�ĵ�������ǿ���ܹ�Ѹ�������ĸ��ġ����һ�������е�����Ƶ��żȻ�ı�ij����ѧ��С����������Ʒ�����ã����Dz�Ӧ������ѧУ���㹻����Դ���������е�ͻȻ֮��Դ˸���Ȥ�����ǽ��п�������Ҫ��
��һ����Ҫ������ԭ����Ŀǰ��ҵ������ά���Ѿ������������������������Ϲ��ڵĵز�����ʵ��������Ҫһ���ܹ�����������͵ļܹ��� ��Щ����Ҫ�Զ�����ʱ�����ȵ����ݵĸ��ơ�
ͬʱ������Ҳ����ϣ���������ò�Ϊ��ͬ���͵������ֹ����ô��̺ͻ���ʱ���Usenet ���Ź���Ա�����ܵ������һ����
����Ҳ����Ը��ѡ��һ���ܹ���������ʹ�ÿ�����Դ�ܹ���õı�������֯��ʹ�����Ż����������Ŀ���Ӧ��ϵͳ���ⲻ�Ǽ����⣬���������һЩ����
• ���ĵ����û����з�����������������ǽ��д�����
• ����Щ�ض�С������ض����ĵ��ĸ�ʹ����������й��ƣ�
• Ϊ���ٴ�ȡ�����ĵ����������λ�ã�
• һ���㷨������URL�Ի�ȡ����˻�������Ŀ�����
��Щ����Ľ���������������һ���ض��ģ���ͬ�Ļ�����ʩ�IJ�ͬ��Χ����ӵ�в�ͬ����Ȩ�����ߵIJ��ֽ���Ļ����С�
��Щ�ǹ��ڻ�����ʩ����ά���Ļ����ܹ����ij��ڵ�˼�������ڿ�����Э��������������HTTPͨѶ����Ч�ԣ��ر����������Щʹ�õ绰Modem���û��������
����ͨѶ
���ڿ���W3C���������ط�Ϊ��ʹ��ά����Ϊһ��ͨѶý�����Ҫ��������Χ���ſ����ڲ�ͬ����ʾ�����ݸ�ʽ�����еģ�HTML�ļ�����չ���µı�Яʽ����ͼ��Portable Network Graphics��PNG)�淶��������ʵ��ģ���ԣ�Virtual Reality Markup Language ��VRML���ȵȡ����Ʋ�������������Ȼ������������HTML����Ϊ���мܹ���һ���֣�������Ȼ������µĸ�ʽ��Ҳ��һ�ֹ��ܸ�ǿ��һ���Ը��õø�ʽ������ȡ��HTML�����ڿ�����������һЩ�ı佫ʹ����ά����������ͨѶ��DZ������ʵ�֡�
�����Ѿ�������ά����������Ŀ���dz�Ϊ���DZ������ǵĹ�����֪ʶ�Ŀռ䡣���ǿ��Կ�������һ��ǿ��Ĺ��ߣ�
• �����ǰ����ǵ�����ŵ�һ�������ı���ʱ����Щ�ı����κ�ʱ�����Ķ�����ͼ�����һ������Ϣ�������Ŀ����ԡ�
• ��һ�����˼���ij��С���ʱ�������ܹ�������ȥ���еľ����ļ�¼�����е���ϣ���Ŀ������ɣ�
• ��һ�����뿪С�飬���ǵĹ����Ѿ���¼��������ν�Ľ�������Ҫ�����桱��
• �������Ϲ���ij����Ŀ�������ĵ�����֯�Ļ��������Ƿdz��������ĵģ�Ҳ�������������ܹ��õ����ڹ���������֯�ĸ������Բ������Ľ��ۡ�
Ŀ������ά��Ӧ���ܳ�Ϊ������Ϣϵͳ���ܳ�Ϊ�κη�Χ����֯�Ĺ���ʹ�ôӶ���С����չ��ȫ�����Զ������̬�����������������������ᵽ��һ�������ϵͳ�ı��ʵĹ��������ܹ�����Щ����ƶ���������Ϣ��ʹ������֮������ӳ�Ϊ�����Ľ��㣬���ڵ���Щ����յ����ǰ�������ά������һ���ԡ�
�ڱ�ƪ����д����ʱ����ά���������ķ�����æ��һ����������������ҵվ�㡣��֯�е���ά����Ҳ������ν��Intranet����õ������ע�⡣���ݶ��壬������ά����˽�ܲ��ֵIJ��ϵ������Ƿdz����ѵġ�Ȼ���������������ٸ������ķ�����ͬʱ��һ�����͵ļ������ҵ���г���100���ڲ������������ܽ���һ��˽�з�������Ҫ���Ƿ��ʿ��Ƶ����⣬���ǣ�һ��������������������һ����֯����ҵ��һ���֣������߹���һ�����εȼ�����һ��ʵ��������ƽ�����ʹ�á�
����ڹ�����Ϣ��Ҫ�������֤���������⽫��ʹ��Ϣ������һ�������Է��ġ�����ֱ�ӵIJ�η�����
�����һ���о���Ŀרע��һЩ��ά��Э���ܹ����Ľ��Ը�������ʹ�õ��������а�����
• ����ֱ�Ӻ���ά�����ݽ��н����ĸ��õı༭����
• ����Ϣ����ʱ�Ը���Ȥ���˽���֪ͨ��
• ��Ƶ��Ƶ������鼼�������ϣ�
• �Կɼ��Ϳɷ����ķ�������������̵�����ij��ı����������۾ݣ�peer���ۺ���������
• ��������ע��������
• ����֤����Ȩ������С���Ա�������ʿ��ƣ�
• ��Ϊ�����汾���ơ����߹�ϵ������Ȩ��ϵ�ĵ�һ���������ӵı�ʾ��
���۵ĽǶȣ���ά��Ӧ���ܹ�����Ȼ�����ڸ�����Ϣϵͳ����ʵ�ϣ�ֻ�е�ȫ�����ݺ���������һ�µķ������д�����ʱ���Dz��Ǻ���Ȼ�ġ����˻��ӿڵĹ۵�������ͨ��ʹ�á����桱�������Ļ����ļ�����ӿ���Ҫʹ�ó��ı��������ϡ��������Dz�û��̫��IJ���ļ�ϵͳ������ά���ĵ�һ��Ҳ�����ӣ���������������ݷ�ʽ���������õ���Ϣ�����������˵�ļ���Ƕ���ļ��б���Ҫת������ά�����Ѿ����ڵı��ķ�ʽ��ֱ���������ڵ��ļ����Ի�����ʧ�ˣ����߲Ų�����ü����ϵͳ�е��ļ�������Ҫ�Իή�͡� ������Ϣ����Ҫ�Ķ����ܹ���õ�ʹ�����ı�����Ը�����ʽ���ڵ���������ʾ,����˵���ļ��������ļ����ڣ��ڡ�To��������ʾ��Ϣ��Email��ַ���ĵ����������ߵĹ�ϵ���ȵȡ���Щ����ḻ�Ķ��Զ�������˵�Ǻ�������ġ�����û�ָ����һЩ��Ϣ�������һƪ�ĵ�����Ҫ�Ŀ����ԺͿɿ��Բ�Σ��ĵ��ɼ��ȷ�Χ��Ȼ��ʣ�µľ���ϵͳ������ѵĴ��̿ռ������ṩ����Ҫ�ķ����������
���ս�������ǿ���ϣ����ά����Ϊһ��һ���Եģ���������ֱ���е���Ϣ���磬���ۺ�ʱ���ǿ��ż������Ļ��������������Ļ��������ҵ���Ļ�������õ���Ļ���ܿ�������һ���֡�
��������ά���Ľ���
�����������ᵽ�ģ���ά����չ��һ�����ںͳ��ڵ�Ŀ������������ܹ���ȷ�ķ�ӳС���֪ʶ�ͺ����ɹ�����ô������������Ϊ�ܹ��������ǽ�����ʽ�ĺ��ƶ�����һ�����Ĺ��ߡ�������ά����ҵӦ�õIJ������ӣ���һĿ�귢չ��������������ƶ���ҵ������ӵ��ִ�в����ܵĸ��˴����ij��֡�
��һ�з�������Ҫ�ĵ�һ�������ĸı�����ά������Щ�����������DZ����;��������һ�ְ�������õ�����Ļ����ɶ�����ʽ��� ����EDI�������ĵ��������ĵ�·����ȥ�������ܹ�ʵ����һĿ�ꡣ��EDI�����Ƿ�����һЩֽ���ĵ��ĵ��ӵȼ������ۣ���Ѻ֤ȯ������Ȩ֤��ͷ�Ʊ��������������ʽ�����屻��������ǿɶ��Ĺ淶��˵������ѡ�ķ������ж���һ���ܹ������������Ե�ͨ�����ԣ����ǻ�����ʱ�������ǿɶ����ĵ��ж��������ĸ�����������������ۺϲ�ͬ����ĸ����������ʹ�������ܹ��������ܸ���ǿ�������Ϊ���ǽ�����������ϵͳ�Ļ�����ϵͳ�� ֪ʶ���KR�����Դ�ij�ֳɶ���˵��һ��ѧ���Ϻ���Ȥ���Ƕ��ڼ������Ӧ��ȴû��ʲô��ԶӰ��Ķ��������ǣ�����ά����ȫ��Χ�ռ�֮ǰ�����ı�Ҳ���������ڻ�������ȫ�����ݺͼ��ܰ�ȫ֮�������һ��˫������ӡ� Ϊ��ʹ�����Ը������������ʹ��Ч�ģ����������ܹ���֤����ά���Ϸ��ֵĶ��Ե���Ч�ԣ������Ҫһ��ȫ�Ļ�����ʩ����֤���ĵ�����ǩ�������Ƶģ�ȫ�İ�ȫ������ʩ�ڹ��ڼ�����Կ�����ε���Ϣ��Ҳ�ƺ���Ҫһ���ܹ����ݸ��Ӷ��Ե������� ��Ҳ�����Ǽ��͵����������ϵ����Щ�������������ڼ��ܵ�ʹ�õ�����ʹ��������ϵͳ�ٳٲ���ʹ�á�PICSϵͳҲ��������һ����ĵ�һ������Ϊ���е��ı��ǻ����ɶ��ġ�
����������ע
��1994��5�������߾��еĵ�һ����ά�������ϣ����ߣ�ָTim������һ���������ԣ�����˵��������ά�����о�����ֻ�Ǵ����ѧ����������������⣬����ʦ�������Э���ʱ�ᷢ�ֺܶ������ĺ����ѧ�����⣬���Dz�Ӧ����Ϊ��Щ������������Ӧ�ý�������⡣���Ժ�ĺ̵ܶ�ʱ���ڣ�����������ֵ�Ƶ��Խ��Խ�ߡ�PICS�����������Э�����ʽ�ҹ�Ӱ�콨������Ϣ�ռ�����ϵ�������ʽ��
������˵�ĸ�����˽Ȩ��ֻ�������ںܴ�Ĺ㳡�м������е�Ȩ���������Dz���ҲӦ����Ϊ��һ��ͨ���������ӵĸ���֮����е�̸��Ҳ������˽�����ǵ�������������Ļ��ڡ���֪ʶ��Ȩ�ĸ����û��ʹ���ܹ�ӳ�䵽�������Ϣ�ռ�ķ��������� ������Ϣ�ռ��У������ܹ����ǵ�������ʾ��Ʒ��ԭ���ߺ����ǵ�˼�룬�������Ǵ�����Ҳ���Կ���Ŀǰ����������Ҫһ��DZ�ڵĻ�����ʩ����֤�ܹ���������Ч�ʺͿɿ��ԵĿ������������ݡ��ø��Ƶķ����������Ȩ�ĸ����Ǻ�������ġ����⣬һ�������Զ��Ľ����˸��ƣ����ʹ�ø���Ʒ�п��ܱ�ռ�У��и�����Ϊ����˽��̸���������������ع⡣ȷʵ���оٳ����е���˽����һ����Э�ķ����Ƿdz����ѵģ���Ϊ��Щԭ�����ֹ��������ڱ�÷dz������ס������ṩ����β��ܹ�������������ҳ��������ͳ�Ƶķ�����������Ҫ����������˽�� ��������С��ʱ�����������Ǻ���ζ�ģ�����������������������������Ǿ�ģ����ܹ���ΪΣ����Ϣ��
���ڿ��������й��ڵ������ĸ��������ɶ�Ԫ�����е�һ����ʱ�����ǵ��Ļ�����������������ʹ��ȫ���綼��ΪһԪ�Ļ�����ʽ�Ļ����������������һ��ȫ�µ�Ŀǰ�����ڵ����漯�ţ� ������ͨ����ѡ�ٵ������ṩ���Ҿ��߱������ʾ���������������������������Ѳ���̵���б��������������֧�ֵ���̫����������Ҫ���������������������Ĺ��̾�������Щ�����Ӱ����������ش�ġ�
����
��ά������Internetһ��������Ƶ�Ŀ���Ǵ��������������ġ��˵��ˡ���Ч����ͬʱ��������������ʵ�ֻ��ơ�������ط��ܹ�ע���һ�㣬�ܹ����ֳ����֡��˵��ˡ������ԣ���ô�����ֻ�����û���������������ij�ͻ�ǺϷ��ģ���Ϊ�ǽ����ƻ��˵��˵ķ����������ܹ�������ȥ�� ������ǣ���ô����ʦ�����ò�ѧϰ���ϵͳ����������֤���ܷ����˴�֮��ʲô���˵��˹��ܶ��ܹ�ʵ�֡�TCP�������DZ�֤�ɿ������ݴ��䣨�ṩ�˵���Ŀǰ���粻���ṩ�ķ����������ܱ�֤�����ԡ�δ����Э�齫��������֤��Ϣ������Ȩ��֧������ЩĿǰΪ�������������Ƶ����ǽ����������ķ��档Ϊ������Ϣ�ռ��Ϊ�ܹ������һ�������ǿ��ռ䣬���������ԣ�������������Ӳ�������ݰ�·�ɡ�����ϵͳ��Ӧ��������Ʒ�ƶ���������Ҫ�ġ��������Ա�����һ�¡��ɿ���ƽ�ȣ����ǹ��ҵķ�����Ҫ������Э��Ĺ淶һ����ʵ����һĿ�ꡣ
����
��ʣ���㹻�Ŀռ����ڰ��������������IJο����ס���ά��������һϵ�е����������žٰ�Ļ��顣����������ĺ�����ά�������������飬���߿ɲμ���ȥ�ͽ����Ļ��顣�������������Ļ���¼����
Proceedings of the Fourth International World Wide Web Conference (Boston 1995), The World Wide Web Journal, Vol. 1, Iss. 1, O'Reilly, Nov. 1995. ISSN 1085-2301, ISBN: 1-56592-169-0. [[Later issues may also be of interest.]
Proceedings of the Fifth Internatonal World Wide Web Conference, Computer Networks and ISDN systems, Vol 28 Nos 7-11, Elsevier, May 1996.
Also refered to in the text:
[1] Bush, Vannevar, "As We May Think", Atlantic Monthly, July 1945. (Reprinted also in the following:)
[2] Nelson, Theodore, Literary Machines 90.1, Mindful Press, 1990
[3] Englebart, Douglas, Boosting Our Collective IQ - Selected Readings, Boostrap Institute/BLT Press, 1995, <AUGMENT,133150,>, ISBN:1-895936-01-2
[5] On Gopher, See F. Anklesaria, M. McCahill, P. Lindner, D. Johnson, D. John, D. Torrey, B. Alberti, "The Internet Gopher Protocol (a distributed document search and retrieval protocol)", RFC 1436 03/18/1993. , http://ds.internic.net/rfc/rfc1436.txt
[6] On EDI, See http://polaris.disa.org/edi/edihome.htp
����������������������������
word��ʽ��

������������������������������
����ܶ����ĺ�ʹ�࣬���Զ�����Ҳ���е�ʹ�࣬ϣ����Ұ�æָ��������
�������������ĵķ���������ѧ������ʹ�ã��������ã�������ԭ���ߵ�����Ȩ�ͷ����ߵ��Ͷ���

 [����] �������ѧ��̳ ��
W3CHINA.ORG������ - Web�¼������� �� �� Semantic Web(����Web)/������/���� �� �� ��ά������ȥ�����ں�δ��[��]
[����] �������ѧ��̳ ��
W3CHINA.ORG������ - Web�¼������� �� �� Semantic Web(����Web)/������/���� �� �� ��ά������ȥ�����ں�δ��[��]



 (���ı���)
(���ı���)




 ������
������









 ��ά������ȥ�����ں�δ��[��]
��ά������ȥ�����ں�δ��[��]